GEMM: General Matrix Multiply(matrix to matrix multiplication)
GEMV: General Matrix Vector Multiplication (matrix to vector multiplication)
Challenges of Quantization
Quantization error
Retraining (Quantization Aware Training)
Limited Hardware support
Calibration dataset needed
packing/unpacking
getting q:-
r = s(q-z) q = int(round(r/s+z))
import torchimport seaborn as snsimport matplotlib.pyplot as pltfrom matplotlib.colors import ListedColormap#Helper functions to visualizedef plot_matrix(tensor, ax, title, vmin=0, vmax=1, cmap=None):""" Plot a heatmap of tensors using seaborn """ sns.heatmap(tensor.cpu().numpy(), ax=ax, vmin=vmin, vmax=vmax, cmap=cmap, annot=True, fmt=".2f", cbar=False) ax.set_title(title) ax.set_yticklabels([]) ax.set_xticklabels([])def plot_quantization_errors(original_tensor, quantized_tensor, dequantized_tensor, dtype = torch.int8, n_bits =8):""" A method that plots 4 matrices, the original tensor, the quantized tensor the de-quantized tensor and the error tensor. """# Get a figure of 4 plots fig, axes = plt.subplots(1, 4, figsize=(15, 4))# Plot the first matrix plot_matrix(original_tensor, axes[0], 'Original Tensor', cmap=ListedColormap(['white']))# Get the quantization range and plot the quantized tensor q_min, q_max = torch.iinfo(dtype).min, torch.iinfo(dtype).max plot_matrix(quantized_tensor, axes[1], f'{n_bits}-bit Linear Quantized Tensor', vmin=q_min, vmax=q_max, cmap='coolwarm')# Plot the de-quantized tensors plot_matrix(dequantized_tensor, axes[2], 'Dequantized Tensor', cmap='coolwarm')# Get the quantization errors q_error_tensor =abs(original_tensor - dequantized_tensor) plot_matrix(q_error_tensor, axes[3], 'Quantization Error Tensor', cmap=ListedColormap(['white'])) fig.tight_layout() plt.show()def linear_q_with_scale_and_zero_point( tensor, scale, zero_point, dtype = torch.int8): scaled_and_shifted_tensor = tensor / scale + zero_point rounded_tensor = torch.round(scaled_and_shifted_tensor) q_min = torch.iinfo(dtype).min q_max = torch.iinfo(dtype).max q_tensor = rounded_tensor.clamp(q_min,q_max).to(dtype)return q_tensortest_tensor=torch.tensor( [[191.6, -13.5, 728.6], [92.14, 295.5, -184], [0, 684.6, 245.5]])scale =3.5zero_point =-70quantized_tensor = linear_q_with_scale_and_zero_point( test_tensor, scale, zero_point)def linear_dequantization(quantized_tensor, scale, zero_point):return scale * (quantized_tensor.float() - zero_point)dequantized_tensor = linear_dequantization( quantized_tensor, scale, zero_point)plot_quantization_errors(test_tensor, quantized_tensor, dequantized_tensor)
Get the Scale and Zero-Point
s = (r_max-r_min)[current_tensor_range]/(q_max-q_min)[datatype_range]
z = int(round(q_min - r_min/s))
z and quantized tensor are of the same type
z is an integer because it represent zero(in the original ‘r’ range) with an integer in the quantized ‘q’ range
if z goes out of range:-
z < q_min:-
z = q_min
z > q_max:-
z = q_max
import torchdef get_q_scale_and_zero_point(tensor, dtype=torch.int8): q_min, q_max = torch.iinfo(dtype).min, torch.iinfo(dtype).max r_min, r_max = tensor.min().item(), tensor.max().item() scale = (r_max - r_min) / (q_max - q_min) zero_point = q_min - (r_min / scale)# clip the zero_point to fall in [quantized_min, quantized_max]if zero_point < q_min: zero_point = q_minelif zero_point > q_max: zero_point = q_maxelse:# round and cast to int zero_point =int(round(zero_point))return scale, zero_point
Symmetric vs Asymmetrci Mode
Assymetric Mode:-
map [r_max, r_min] to [q_max, q_min]
This is what we have implemnted above
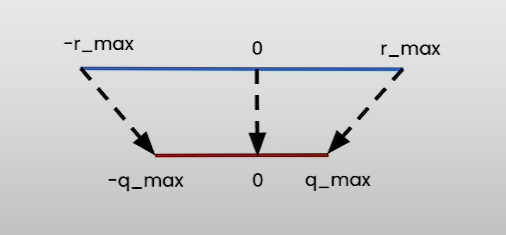
Symmetric Mode:-
map [-r_max, r_max] to [-q_max, q_max]
where r_max = max(|tensor|)
We don’t need to use zero point(z=0). this happens because the floating point range and the quantized range are symmetric with respect to zero
Hence, we can simplify the equation to:-
q = int(round(r/s))
s = r_max/q_max
import torchdef get_q_scale_symmetric(tensor, dtype=torch.int8): r_max = tensor.abs().max().item() q_max = torch.iinfo(dtype).max# return the scalereturn r_max/q_maxdef linear_q_symmetric(tensor, dtype=torch.int8): scale = get_q_scale_symmetric(tensor) quantized_tensor = linear_q_with_scale_and_zero_point(tensor, scale=scale,# in symmetric quantization zero point is = 0 zero_point=0, dtype=dtype)return quantized_tensor, scale
Trade-off
Utilization of quantized range:
when using asymmetric quantization, the quantized range is fully utilized
When symmetric mode, if the float range is biased towards one side, this will result in a quantized range where a part of the range is dedicated to values that we’ll never see.(e.g ReLU where the output is positive)
Simplicity:
Symmetric mode is much simpler compared to asymmetric mode.
Memory: We don’t have to store zero-point for symmetric quantization
We use symmetric quantization for 8-bit, but as we go for lower bits such as 2 or 4 bits, we use asyyemtric quantization
Finer Granularity for more Precision
Different granularities
per tensor
per channel (along an axis)
per group (group n elements together)
The more granular quantization is the more precise it will be.
RuntimeError : Only Tensors of floating point and complex dtype can require gradients
When we create nn.Parameters, pytorch expects that parameter where it’s able to compute gradients on it.
The issue is that with PyTorch, you can’t explicitly compute gradients on INT8 tensors.
So above code snippet will give an error saying that only tensors of floating point and complex dtype can require gradients.
So the right approach to save INT8 weights is instead of saving attributes as being an endless parameter, is to call the method called register buffer.
This way instead of storing a parameter, we just store a buffer, meaning we don’t need to compute gradients on the tensor.
You can initialize it with whatever dtype you want.
import torchimport torch.nn as nnimport torch.nn.functional as Fclass W8A16LinearLayer(nn.Module):def__init__(self, in_features, out_features, bias=True, dtype=torch.float32):super().__init__()self.register_buffer("int8_weights", torch.randint(-128, 127, (out_features, in_features), dtype=torch.int8 ) )self.register_buffer("scales", torch.randn((out_features), dtype=dtype)) # We are intereseted in inference onlyif bias:self.register_buffer("bias", torch.randn((1, out_features), dtype=dtype))else:self.bias =Nonedef forward(self, input):return w8_a16_forward(self.int8_weights, input, self.scales, self.bias)
Also don’t try to change the lm_head otherwise it will not give the desired results
All the rounding errors can sum up once you start generating a lot of tokens, until may be all of these errors get super large so that it affects the model’s performance
Load your Quantized Weights from HuggingFace Hub
The idea is to quantize weights on bigger instance and then push it back to huggingface. So that we don’t have to load and quantize again and again.
Then use meta device from pytorch to load the skeleton of the model instead of loading the whole model itself.
Replace the original layers with the quantized layers
import torchfrom transformers import OPTForCausalLM, AutoTokenizer, AutoConfigmodel_id ="facebook/opt-125m"config = AutoConfig.from_pretrained(model_id)with torch.device("meta"): model = OPTForCausalLM(config)tokenizer = AutoTokenizer.from_pretrained(model_id)for param in model.parameters():print(param)break
/home/ritesh/miniconda3/envs/quarto/lib/python3.10/site-packages/huggingface_hub/file_download.py:942: FutureWarning: `resume_download` is deprecated and will be removed in version 1.0.0. Downloads always resume when possible. If you want to force a new download, use `force_download=True`.
warnings.warn(
/tmp/ipykernel_29119/1695582919.py:1: FutureWarning: You are using `torch.load` with `weights_only=False` (the current default value), which uses the default pickle module implicitly. It is possible to construct malicious pickle data which will execute arbitrary code during unpickling (See https://github.com/pytorch/pytorch/blob/main/SECURITY.md#untrusted-models for more details). In a future release, the default value for `weights_only` will be flipped to `True`. This limits the functions that could be executed during unpickling. Arbitrary objects will no longer be allowed to be loaded via this mode unless they are explicitly allowlisted by the user via `torch.serialization.add_safe_globals`. We recommend you start setting `weights_only=True` for any use case where you don't have full control of the loaded file. Please open an issue on GitHub for any issues related to this experimental feature.
state_dict = torch.load(r"/home/ritesh/github_repos/riteshrm.github.io/tmp/quantized_state_dict.pth")
<All keys matched successfully>
from transformers import pipelinepipe = pipeline("text-generation", model=model, tokenizer=tokenizer)pipe("Hello today I am", max_new_tokens=40)pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)pipe("Hello today I am giving a course about", max_new_tokens=10)
[{'generated_text': 'Hello today I am giving a course about the new generation of the Internet.\nI am'}]
Weights Packing
Weights packing is important for storing quantized weights, because torch.int4 is not available as of today, so we need to store and load the weights in int8
This is not ideal because:
tensor will occupy 8-bit per datapoint and might add a considerable overhead for large models
There would be no point of quantizing to 2/4 bits becuase we are still using 8-bit
So, we need to pack values
Consider a tensor with 4 values each with 2-bit(0,1,2,3) precision but stored in 8-bit
Emergent features at scale:- Simply some characteristics or features which appear at scale, when model is large.
Features predicted by the model meaning the magnitude of the hidden states started to get large thus making the classic quantization schemes quite obsolete, which led to classic linear quantization algorithms just failing on these models.
Now how to deal with outlier features for LLMs
Outlier features simply means hidden states with large magnitude.
So there are some interesting papers such as LLM.int8, SmoothQuant, AWQ.
LLM.int8 separates the matmul in two steps:-
For non-outliers (smaller values)
Perform matmul in int8, then dequantize it.
For outliers (larger values)
Perform matmul in classical way(basically in the dtype of hidden states usually half precision and then you combine these results)
SmoothQuant
Applies A8W8 scheme(quantize weights and activations)
Given an input it determines some factor and use it to quantize.
migrates the scale variance from activations to weights to reduce the quantization difficulty of activations.
the smoothed activation and the adjusted weight are both easy to quantize.
AWQ
Used a calibration dataset to find out which weights could be responsible of generating outlier features called salient weights.
and then use that information to scale the weights before quantization and also use that scale during inference to rescale the input as well.